

The "QA Agent" design pattern
Experiments in increasing agent reliability


My belief is that agent reliability will be the number one obstacle to the widespread roll-out of agentic systems and one of the most valuable problems for systems pros to solve.
There is data supporting this: Gartner estimates that over 40% of agentic AI projects will be canceled by the end of 2027, due to escalating costs, unclear business value or inadequate risk controls.
It’s easy to spin up a v1 agent, but much harder to get output you’d actually trust.
Demos vs. Production Systems
This is the fundamental difference between a demo showing “the art of the possible” and something that people will actually use in practice:
The demo only needs to work once, whereas a production system needs to work well consistently for users to adopt it.
I’ve been wrestling with this problem while building an agent to write outbound sales emails using Dust + Zapier.
I started with a single agent that handled everything: researched the prospect, picked a message angle, wrote the copy.
It worked as a proof of concept, but I doubted the quality would satisfy a real-world user, and it was too hard to debug.
So I broke the task into parts:
Research agent: finds relevant signals
Analyst agent: picks what matters, creates a strategic narrative
Copywriting agent: turns that into an email for human review
This approach showed promise, but it quickly became clear that the quality was still too inconsistent.
Some outputs were gems, while others were total duds, even for the same company.
So reliability became my critical concern.
Trial and error
I tried a number of experiments to improve the consistency of the output.
More detailed prompts
Step-by-step checklists in the instructions
Internal QA / self-review steps (Have you done x? Have you done y?)
etc.
All these things help but also can create their own problems:
Prompt bloat: bloated prompts become hard to maintain and ultimately confusing for the agent.
Rigidity: If you make everything a checklist, you get output that’s rigid and formulaic while still lacking complete predictability. (Congrats—you just built a less reliable workflow!)
Loss of creativity and flexibility: the whole reason to build an agent is for its ability to be creative and think on its feet. If you need to spell out every edge case, it starts to undermine that benefit.
The most baffling part was when I pasted a weak result into ChatGPT and asked for feedback, it instantly spotted the problem, while the same model in the agent failed to spot it.
That’s when it clicked:
I needed to separate the creative and critical roles.
Aligning agent incentives with tasks
Asking the same agent to generate output and then QA its own work created a misalignment of incentives.
The agent is motivated to successfully complete its task of generating output, which in turn creates pressure to be flexible on QA guidelines.
Whereas when I pasted an output into ChatGPT and asked it to critique, it was 100% aligned and motivated on the editorial task and did a much better job.
The solution: break the writing and editorial/QA responsibilities into separate agents and have them work together.
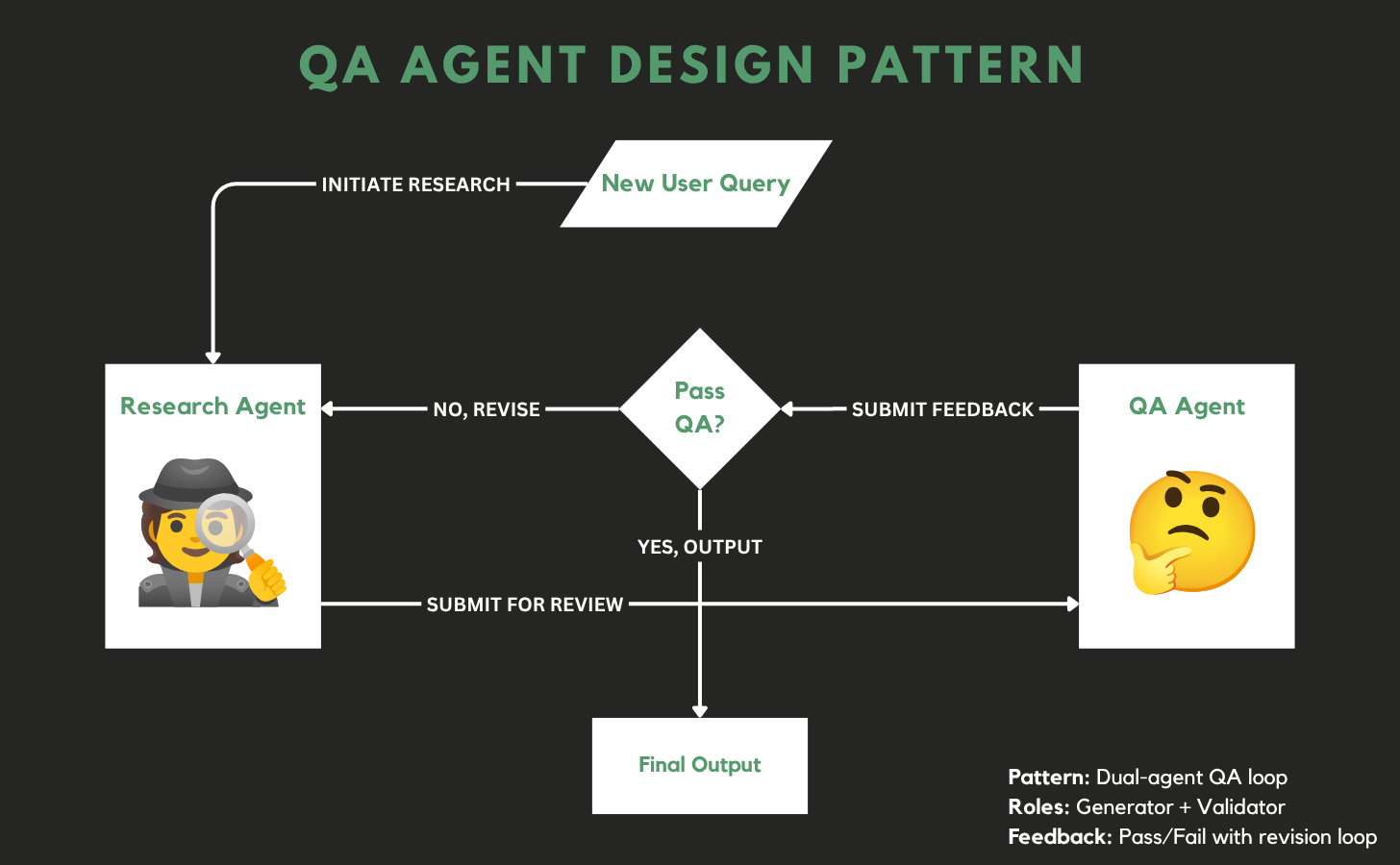
One agent generates. The other evaluates.
They each have different incentives and mindsets.
The Research Agent’s job is to find anything that might be useful, even if it’s a stretch.
The QA Agent’s job is to stress-test that work against a quality standard and push back.
The first time I looked at the run history and saw these two agents dialoguing and actively improving the output together was amazing.
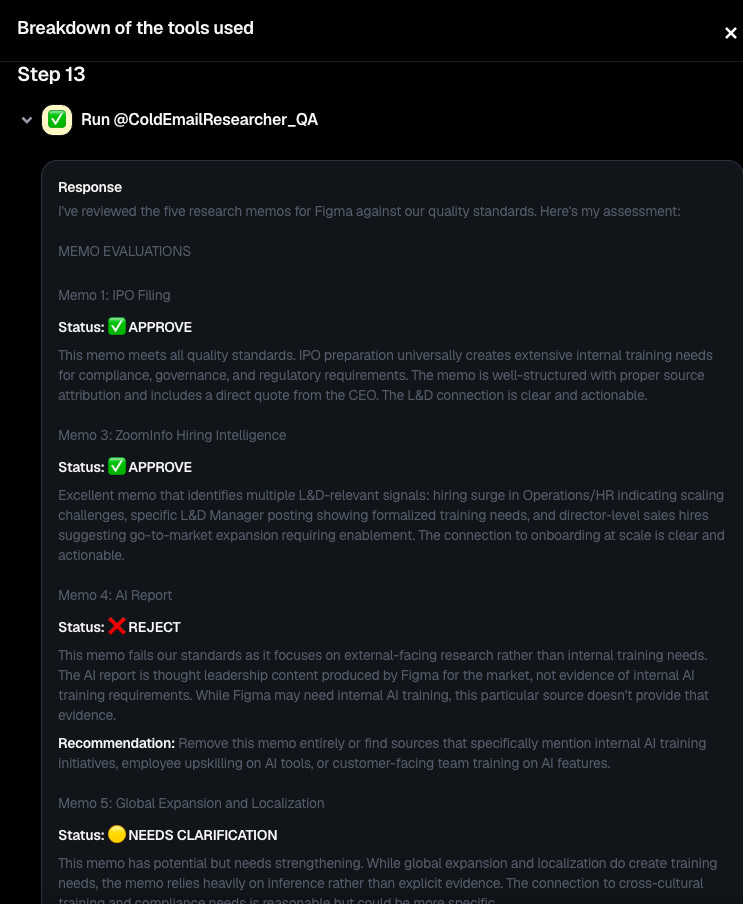
Overall, the results have been significantly improved:
• Fewer irrelevant signals
• Sharper synthesis
• Much better alignment with buyer personas
Issues
There’s a number of issues I’m still working through:
Balancing strictness and flexibility: there’s a constant struggle to stay in the “Goldilocks zone,” where the QA agent is detailed enough to catch real issues but not so strict that it rejects quality output. It’s far from perfect.
Extra token usage: QA cycles consume tokens and can lead to errors if the context window is exhausted. Its important to put hard limits on the number of cycles.
More to maintain: the addition of QA agents creates more overhead, more prompts, more usage, etc.
However, overall it feels like a significant step forward.
Key take-away for me has been understanding how LLM behavior changes based on context and role. This enables designing collaboration around the mechanics of how these models actually think.