

From call recordings to marketing attribution: a step-by-step guide
Turn your call recordings into an insights engine with this AI workflow


Marketers love to argue about attribution, but I find the best signal is often the simplest:
Just ask buyers how they found you.
We encourage our sales team to ask this question, and it’s always fascinating to listen to the responses in call recordings.
It’s not just what they say. It’s also how they explain it. This sheds light on their mindset when researching and choosing vendors and can be far more illuminating than just a generic category.
Example 1
"How did you hear about us?" category: Meetup
What this might tell you: invest in sponsoring local events (?)
Raw text: "I was at the Silicon Valley GTM engineers meetup and some people there had heard about you from their VCs"
What this might tell you: your audience is bleeding-edge, tech forward, and trusts their network more than conventional social proof.
Example 2
"How did you hear about us?" category: Online Research
What this might tell you: Limited insight
Raw text: "We're not happy with our current XYZ, so I did some Google research and found a page on the best XYZs, and you were on it.
What this might tell you: buyers are more conventional and look for validation in traditional online social proof like listicles and G2 reviews. All this is to say—these answers are gold for marketers.
But they’re also typically locked away in call recordings. The data is unstructured, unquantifiable, and hard to act on.
Let’s change that! Today I’ll share a workflow that
unlocks attribution data in calls
structures it cleanly without losing the original voice of the customer
pipes it into slack/email/a database/ wherever you want
I’m going to walk through how to build it step by step, with examples of prompts and code.
Before we dive in…
…here are a few things to keep in mind.
It’s tool agnostic
I personally built this using Retool Workflows, but you could also do it in N8N, Zapier, Workato, Tray, etc.
We all have our favorite tools, but the design patterns are far more fundamental and important.
So with this in mind, you can adapt it to your tool of choice.
Don’t fear the code
If, like me, you approach automation from a non-development background, the use of code can seem a bit intimidating.
But the wonderful thing about working with LLMs is that they open many doors that would previously be for developers only.
Whether you’re using ChatGPT, Claude, or Gemini, it’s trivial to create code steps with sophisticated business logic.
There’s a video walk-through
I also walked through this build in detail on Brandon Redlinger’s podcast, Stack & Scale. So if you’re more of a visual learner, you can watch the full thing here:
Gong Insights Workflow Pattern
Let’s dive in to the step-by-step guide.
Prerequisites
A conversational Intelligence tool (e.g., Gong) with API access and scope to read calls, trackers, and transcripts.
A tracker for the topic you want to analyze, so you can identify the subset of calls that are interesting to you
A workflow tool that supports LLM steps
A destination, like a database (Snowflake), Slack/email, or a sheet with a table to store results
Replace all bracketed placeholders like {{...}} with your values.
👉 All code steps below are LLM-generated; use at your own risk.
High‑Level Flow
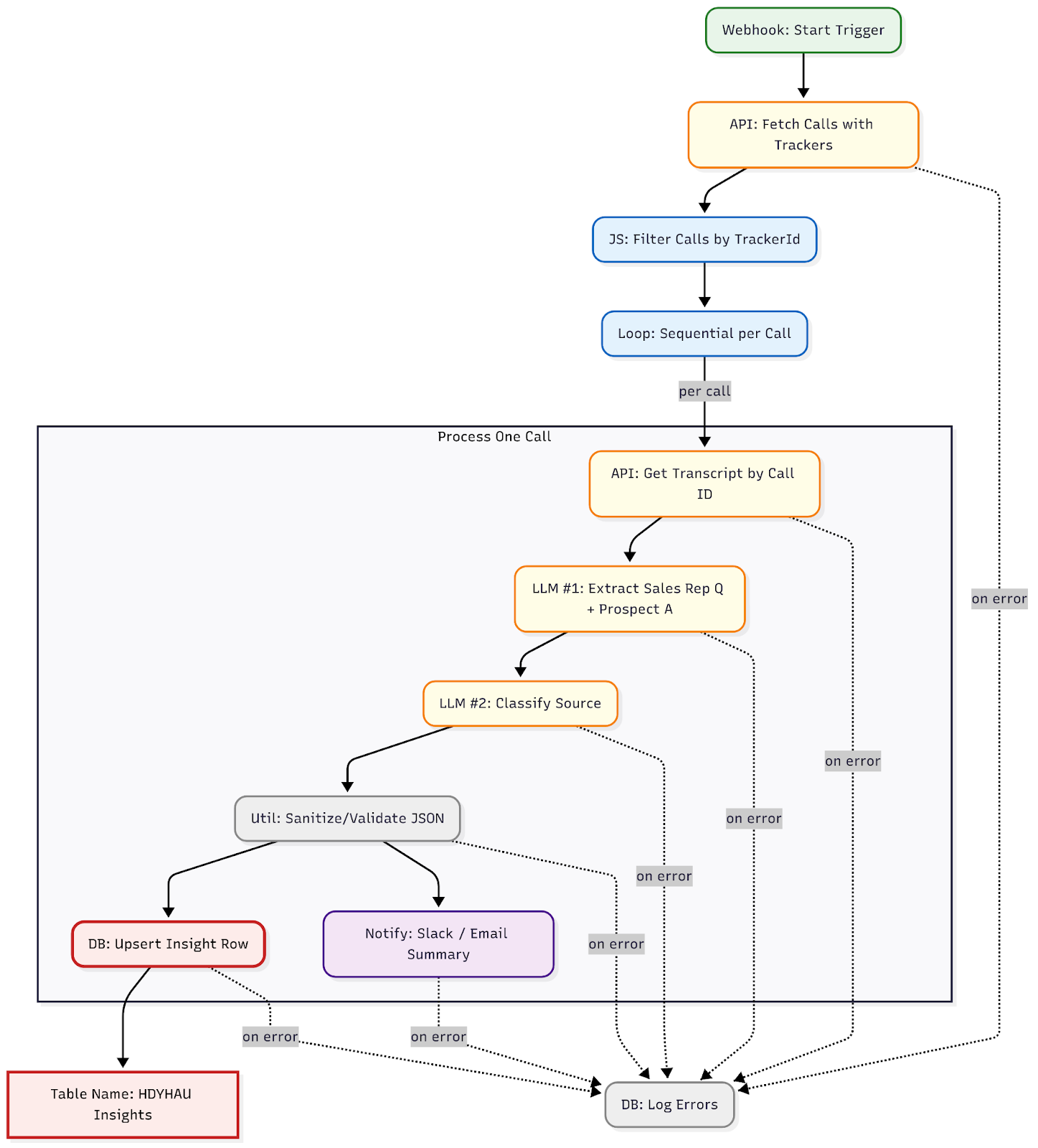
Step‑by‑Step Build
1) Trigger (Schedule or Webhook)
Must accept the following variables:
{
"gong_tracker_id": "{{TRACKER_ID}}",
"from": "{{ISO_8601}}",
"to": "{{ISO_8601}}"
}These variables tell your workflow:
This is the subject I want to track
This is the date range to look at
2) Fetch recent calls
Make a REST API call to Gong’s v2/calls/extensive endpoint.
Headers: Content-Type: application/json
Body (example):
{
"filter": {
"fromDateTime": "{{ body.from ||
moment().subtract(14,'days').startOf('day').toISOString() }}",
"toDateTime": "{{ body.to || moment().endOf('day').toISOString()
}}"
},
"contentSelector": {
"exposedFields": { "content": { "trackers": true, "brief": true } }
}
}This returns an array calls[] for that date range with content.trackers[] and content.brief.
If your time window includes more than 100 calls, you’ll need to handle pagination.
3) Filter calls by tracker
Next, you need to filter the calls down to the subset that interests you.
This could be based on tracker or any other property exposed by the API (e.g., call type, industry, etc.).
Example JavaScript Query
// Inputs
action.params = { targetTrackerId: body.gong_tracker_id };
const targetTrackerId = action.params.targetTrackerId;
const allCalls = get_calls.data.calls || [];
const matchingCalls = allCalls.filter(call => {
const trackers = call.content?.trackers || [];
return trackers.some(t => t.id === targetTrackerId && t.count > 0);
});
// Shape minimal call payload for the loop
return matchingCalls.map(call => ({
id: call.metaData.id,
title: call.metaData.title,
started: call.metaData.started,
url: call.metaData.url,
brief: call.content?.brief || ""
}));4) Loop over matching calls
Next we loop over each matching call to analyze them one at a time.
Have the following steps inside your loop.
5a) Get transcript
The call search endpoint returns metadata about the call but not the transcript.
To fetch it, make a REST API call to Gong’s /v2/calls/transcript endpoint with the call id.
{
"filter": { "callIds": [ "{{ call_id }}" ] }
}5b) LLM — Extract the verbatim “How did you hear about us?” segment
We want to decompose the AI steps as much as possible to maximize reliability.
In this first AI step, the job is ONLY to find the mention of the topic that interests you.
Note, this workflow models a simpler pattern that assumes only a single mention. However, some topics might have multiple mentions in a call. In that case, this step should produce an array of all the relevant mentions, and then another sub-loop should analyze them each individually.
Model: your choice (e.g., gemini‑2.5‑pro, GPT, Claude). Choose something with a longer context window to handle the full transcript.
Prompt:
ROLE
Your job is to analyze the provided call transcript text. Find the portion where the salesperson asks how the prospect heard about the company and the prospect answers.
RESPONSIBILITIES
1) Locate the question/answer pair.
2) Extract them verbatim.
3) Return JSON only with keys:
{
"sales_rep": "verbatim question",
"prospect": "verbatim answer"
}Do not include any commentary or markdown.
IF NOT FOUND
Return the exact string:
"Based on the transcript provided, the sales representative does not ask the prospect how they heard about us."
INPUT
{{ callTranscripts }}
5c) LLM — Classify the excerpt
The next LLM step will perform the analysis. The specifics will vary based on what you want to analyze—it could be classification, insight extraction, etc.
In this case, we’re classifying.
Labels (edit as needed):
Word of Mouth, Podcast, Email, LinkedIn, Event, LLM Recommendation, Online Research, Partner, Employee, N/AInstruction:
You will receive the verbatim Q/A excerpt. Classify the prospect’s answer into one or more categories from the provided label set. If unclear, return N/A.
Output JSON:
{
"excerpt": "verbatim prospect answer for context",
"classification": ["Label1", "Label2"],
"rationale": "1-2 sentences explaining your choice"
}INPUT
{{ extract_excerpt.data }}
5d) Sanitize JSON (defensive parsing)
Depending on your automation tool, the LLM step may return only a string that looks like JSON.
Even worse, it may add extraneous characters like ```json around it, even when you ask it not to!
You need to sanitize and JSONify this string so it can be analyzed properly or used in later steps.
I use this utility code in Retool, which covers the main errors I’ve seen. You may need to modify it (or ask an LLM to) for your purposes.
function sanitizeJson(raw, defaultValue = {}) {
if (typeof raw === 'object' && raw !== null) {
return raw;
}
let text = String(raw || '').trim();
text = text.replace(/^```[\w-]*\s*|\s*```$/g, '').trim();
try {
return JSON.parse(text);
} catch (e) {
console.log("Failed to parse JSON from AI:", e.message);
return defaultValue;
}
}
// Params come from the parent workflow call
const raw = startTrigger.data.raw;
const defaultValue = startTrigger.data.defaultValue || {};
const result = sanitizeJson(raw, defaultValue);
return result; // <-- makes it available as sanitize_json.data5e) Upsert to your database
The end result is a beautiful, clean object with the data and insights you want.
It looks something like this:
{
"excerpt":"You know I’ve really been doing a lot of Google research. I’m not sure exactly where I saw you guys. I did ask chatgpt about the best software, and that may have been the first place.",
"classification":["Online Research","LLM Recommendation"],
"rationale":"The prospect mentions two potential sources: doing 'Google research,' which falls under Online Research, and asking 'chatgpt,' which is an LLM Recommendation."
}You can map the internal parts of this object to the relevant fields in your Google sheet or database.
5f) Optional: Additional activation steps
Send to Slack
Send an email alert
Write back to a Salesforce field
5g) Error logging (global)
Write errors to a dedicated table whenever any loop item fails.
Configuration notes and guardrails
Use code / rules where you can: even though this is an “AI workflow,” it’s still mostly deterministic logic. That’s by design. It means you maximize reliability while leveraging the flexibility of AI where it counts.
Use small, reliable LLM steps: one model call to extract, one to classify. Keep prompts short and outputs strictly JSON.
Rate limits: throttle the loop (e.g., 1 call/sec) to respect API and model limits.
Idempotency: upsert by call_id to avoid duplicates on reruns.
Redaction: store only the minimal excerpt; avoid saving full transcripts unless required.
Testing: start with a narrow date range and one label to validate the pipeline.
Going further: building a market insights engine
Although this example is focused on extracting attribution insights, if you take a step back, you realize it’s essentially a calls-to-insights pipeline that is subject agnostic.
This pattern could be applied to any topic you might be interested in:
Problem identification
What: how customers describe their pains and problems
Applications: landing page copy, ad copy, social post ideation
Competitive Intelligence
What: how prospects feel about your competitors, details from competitive sales cycles
Applications: improve battle cards, sales enablement, positioning
Product features
What: mentions of specific features or requested capabilities
Applications: feature validation, roadmap planning
….and so on.
If you discover any other interesting applications, I’d love to hear about them.